Unicode、UTF-16、UTF-8相互转换
本文从wiki和其它博文中搬了一些定义
字符和字节的区别
字节(Octet): 是一个八位的存储单元,也称为Byte
字符(Character): 逻辑上的字,像「A」,「是」,「😝」都是一个字符
Unicode和UTF
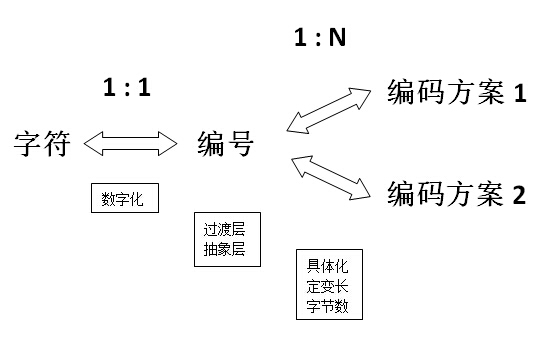
Unicode是为了解决传统的字符编码方案的局限而产生的。类似所有字符的集合,每一个字符在Unicode中都有唯一『编码』,这个值称为代码点(code point),通常会用“U+”然后紧接着一组十六进制的数字来表示这一个字符。在基本多文种平面(英文:Basic Multilingual Plane,简写BMP。又称为“零号平面”、plane 0)里的所有字符,要用四个数字(即两个char,16bit ,例如U+4AE0,共支持六万多个字符);在零号平面以外的字符则需要使用五个或六个数字。
一个字符的Unicode编码是确定的。但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode/UCS Translation Format,简称为UTF)。
Unicode.org定义了百万个以上的字符,如果将所有的字符用大小表示,需要的是4个字节。“a“的Unicode表示就会变成0x00000061,而“一“的Unicode值是0x00004E00。实际上,这就是UTF32,Linux操作系统上所使用的Unicode方案。而Windows平台下默认的Unicode编码方式为Little Endian的UTF-16。
utf-32编码规则
UTF-32用四个字节表示代码点,这样就可以完全表示UCS-4的所有代码点,而无需像UTF-16那样使用复杂的算法。与UTF-16类似,UTF-32也包括UTF-32、UTF-32BE、UTF-32LE三种编码,UTF-32也同样需要BOM字符。仅用’ABC’举例:

但是,仔细分析可以发现,其实绝大部分字符只使用2个字节就可以表示了。英文的Unicode范围是0x0000-0x007F,中文的Unicode范围是0x4E00-0x9F**,真正需要扩展到4个字节来表示的字符少之又少,所以有些系统直接使用2个字节来表示Unicode。比如Windows系统上,Unicode就是两个字节的。对于那些需要4个字节才能表示的字符,使用一种代理的手法来扩展(其实就是在低两个字节上做一个标记,表示这是一个代理,需要连接上随后的两个字节,才能组成一个字符)。这样的好处是大量的节约了存取空间,也提高了处理的速度。这种Unicode表示方法就是UTF16。一般在Windows平台上,提到Unicode,那就是指UTF16了。
utf-16编码规则
UTF-16由RFC2781规定,它使用两个字节来表示一个代码点。
不难猜到,UTF-16是完全对应于UCS-2的,即把UCS-2规定的代码点通过Big Endian或Little Endian方式直接保存下来。UTF-16包括三种:UTF-16,UTF-16BE(Big Endian),UTF-16LE(Little Endian)。
UTF-16BE和UTF-16LE不难理解,而UTF-16就需要通过在文件开头以名为BOM(Byte Order Mark)的字符来表明文件是Big Endian还是Little Endian。BOM为U+FEFF这个字符。
其实BOM是个小聪明的想法。由于UCS-2没有定义U+FFFE,因此只要出现 FF FE 或者 FE FF 这样的字节序列,就可以认为它是U+FEFF,并且可以判断出是Big Endian还是Little Endian。
举个例子。“ABC”这三个字符用各种方式编码后的结果如下:

Windows平台下默认的Unicode编码为Little Endian的UTF-16(即上述的 FF FE 41 00 42 00 43 00)。你可以打开记事本,写上ABC,然后保存,再用二进制编辑器看看它的编码结果。
utf-8编码规则
UTF-16和UTF-32的一个缺点就是它们固定使用两个或四个字节,这样在表示纯ASCII文件时会有很多00字节,造成浪费。而RFC3629定义的 UTF-8则解决了这个问题。UTF-8用1~4个字节来表示代码点。表示方式如下:
|
代码范围 十六进制 |
标量值(scalar value) 二进制 |
UTF-8
十六进制 |
注释 |
|---|---|---|---|
|
000000 - 00007F
128个代码 |
00000000 00000000 0zzzzzzz | 0zzzzzzz(00-7F) | ASCII字符范围,字节由零开始 |
| 七个z | 七个z | ||
|
000080 - 0007FF 1920个代码 |
00000000 00000yyy yyzzzzzz | 110yyyyy(C0-DF) 10zzzzzz(80-BF) | 第一个字节由110开始,接着的字节由10开始 |
| 三个y;二个y;六个z | 五个y;六个z | ||
|
000800 - 00D7FF 00E000 - 00FFFF 61440个代码 注1 |
00000000 xxxxyyyy yyzzzzzz | 1110xxxx(E0-EF) 10yyyyyy 10zzzzzz | 第一个字节由1110开始,接着的字节由10开始 |
| 四个x;四个y;二个y;六个z | 四个x;六个y;六个z | ||
|
010000 - 10FFFF 1048576个代码 |
000wwwxx xxxxyyyy yyzzzzzz | 11110www(F0-F7) 10xxxxxx 10yyyyyy 10zzzzzz | 将由11110开始,接着的字节由10开始 |
| 三个w;二个x;四个x;四个y;二个y;六个z | 三个w;六个x;六个y;六个z |
可见,ASCII字符(U+0000~U+007F)部分完全使用一个字节,避免了存储空间的浪费。而且UTF-8不再需要BOM字节。
另外,从上表中可以看出,单字节编码的第一字节为[00-7F],双字节编码的第一字节为[C2-DF],三字节编码的第一字节为[E0-EF]。这样只要看到第一个字节的范围就可以知道编码的字节数。这样也可以大大简化算法。
参考
[wiki:UTF-8]a
字符编码问题,UNICODE\UTF-8\UTF-16\UTF-32\UCS\ANSI\GBK\GB2312等乱七八糟的名词 – 浅显易懂的说明字符编码,还有Big Endian和Little Endian的说明